#include <Index.h>
Inheritance diagram for HashIndex:
Public Member Functions | |
| DbRetVal | insert (TableImpl *tbl, Transaction *tr, void *indexPtr, IndexInfo *info, void *tuple, bool undoFlag) |
| DbRetVal | remove (TableImpl *tbl, Transaction *tr, void *indexPtr, IndexInfo *info, void *tuple, bool undoFlag) |
| DbRetVal | update (TableImpl *tbl, Transaction *tr, void *indexPtr, IndexInfo *info, void *tuple, bool undoFlag) |
Static Public Member Functions | |
| static unsigned int | computeHashBucket (DataType type, void *key, int noOfBuckets) |
Definition at line 88 of file Index.h.
| unsigned int HashIndex::computeHashBucket | ( | DataType | type, | |
| void * | key, | |||
| int | noOfBuckets | |||
| ) | [static] |
Definition at line 48 of file HashIndex.cxx.
References hashString(), typeBinary, typeByteInt, typeDate, typeDecimal, typeDouble, typeFloat, typeInt, typeLong, typeLongLong, typeShort, typeString, typeTime, typeTimeStamp, and typeULong.
Referenced by insert(), TupleIterator::open(), remove(), and update().
00050 { 00051 switch(type) 00052 { 00053 case typeInt: 00054 { 00055 int val = *(int*)key; 00056 return val % noOfBuckets; 00057 break; 00058 } 00059 case typeLong: 00060 { 00061 long val = *(long*)key; 00062 return val % noOfBuckets; 00063 break; 00064 } 00065 case typeULong: 00066 { 00067 unsigned long val = *(unsigned long*)key; 00068 return val % noOfBuckets; 00069 break; 00070 } 00071 case typeLongLong: 00072 { 00073 long long val = *(long long*)key; 00074 return val % noOfBuckets; 00075 break; 00076 } 00077 case typeShort: 00078 { 00079 short val = *(short*)key; 00080 return val % noOfBuckets; 00081 break; 00082 } 00083 case typeByteInt: 00084 { 00085 ByteInt val = *(ByteInt*)key; 00086 return val % noOfBuckets; 00087 break; 00088 } 00089 case typeDate: 00090 { 00091 int val = *(int*)key; 00092 return val % noOfBuckets; 00093 break; 00094 } 00095 case typeTime: 00096 { 00097 int val = *(int*)key; 00098 return val % noOfBuckets; 00099 break; 00100 } 00101 case typeTimeStamp: 00102 { 00103 TimeStamp val = *(TimeStamp*)key; 00104 //TODO return val % noOfBuckets; 00105 break; 00106 } 00107 case typeDouble: 00108 { 00109 //TODO 00110 break; 00111 } 00112 case typeFloat: 00113 { 00114 //TODO 00115 break; 00116 } 00117 case typeDecimal: 00118 { 00119 //TODO::for porting 00120 } 00121 case typeString: 00122 { 00123 unsigned int val = hashString((char*)key); 00124 return val % noOfBuckets; 00125 } 00126 case typeBinary: 00127 { 00128 //TODO 00129 } 00130 default: 00131 { 00132 break; 00133 } 00134 } 00135 return -1; 00136 }
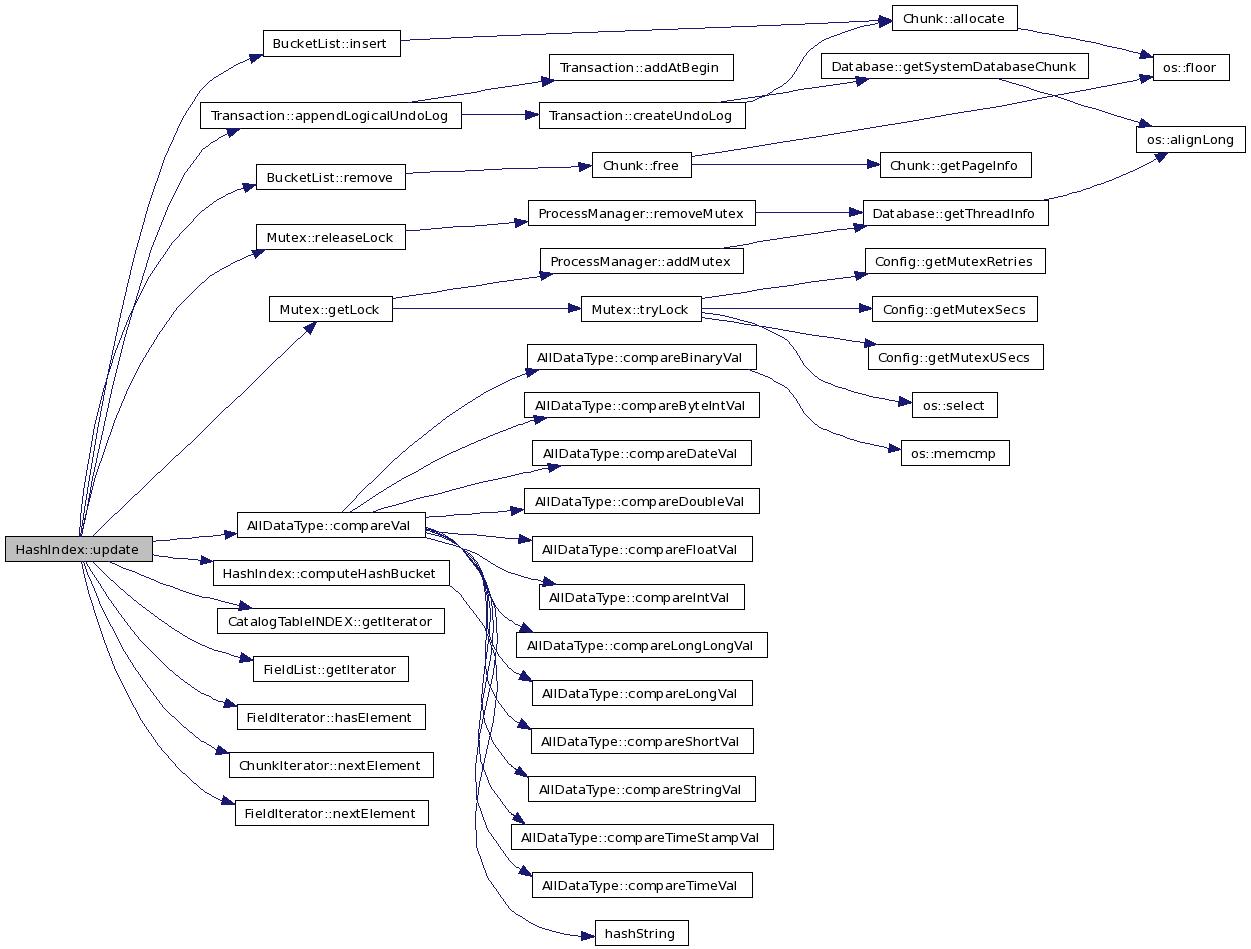
Here is the call graph for this function:

Here is the caller graph for this function:

| DbRetVal HashIndex::insert | ( | TableImpl * | tbl, | |
| Transaction * | tr, | |||
| void * | indexPtr, | |||
| IndexInfo * | info, | |||
| void * | tuple, | |||
| bool | undoFlag | |||
| ) | [virtual] |
Implements Index.
Definition at line 139 of file HashIndex.cxx.
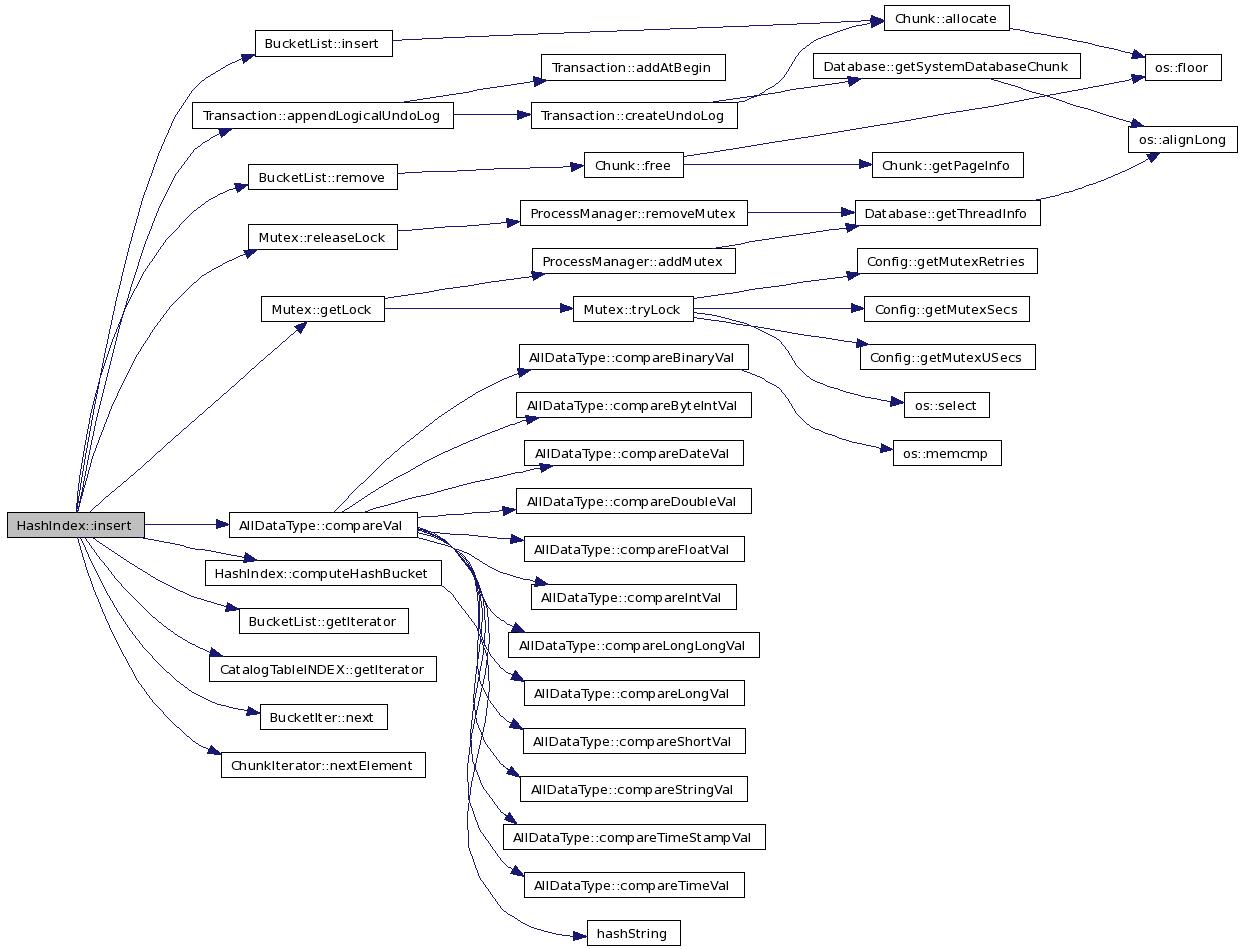
References Transaction::appendLogicalUndoLog(), Bucket::bucketList_, AllDataType::compareVal(), computeHashBucket(), TableImpl::db_, DM_HashIndex, ErrLockTimeOut, ErrSysFatal, ErrUnique, SingleFieldHashIndexInfo::fldName, BucketList::getIterator(), CatalogTableINDEX::getIterator(), Mutex::getLock(), INDEX::hashNodeChunk_, BucketList::insert(), InsertHashIndexOperation, SingleFieldHashIndexInfo::isUnique, SingleFieldHashIndexInfo::length, Bucket::mutex_, BucketIter::next(), HashIndexNode::next_, ChunkIterator::nextElement(), SingleFieldHashIndexInfo::noOfBuckets, SingleFieldHashIndexInfo::offset, OK, OpEquals, printDebug, printError, Database::procSlot, HashIndexNode::ptrToKey_, HashIndexNode::ptrToTuple_, Mutex::releaseLock(), BucketList::remove(), TableImpl::sysDB_, and SingleFieldHashIndexInfo::type.
00140 { 00141 SingleFieldHashIndexInfo *info = (SingleFieldHashIndexInfo*) indInfo; 00142 INDEX *iptr = (INDEX*)indexPtr; 00143 DbRetVal rc = OK; 00144 DataType type = info->type; 00145 char *name = info->fldName; 00146 int offset = info->offset; 00147 int noOfBuckets = info->noOfBuckets; 00148 int length = info->length; 00149 00150 printDebug(DM_HashIndex, "Inserting hash index node for field %s", name); 00151 ChunkIterator citer = CatalogTableINDEX::getIterator(indexPtr); 00152 Bucket* buckets = (Bucket*)citer.nextElement(); 00153 void *keyPtr =(void*)((char*)tuple + offset); 00154 00155 int bucketNo = computeHashBucket(type, 00156 keyPtr, noOfBuckets); 00157 printDebug(DM_HashIndex, "HashIndex insert bucketno %d", bucketNo); 00158 Bucket *bucket = &(buckets[bucketNo]); 00159 00160 int ret = bucket->mutex_.getLock(tbl->db_->procSlot); 00161 if (ret != 0) 00162 { 00163 printError(ErrLockTimeOut,"Unable to acquire bucket Mutex for bucket %d",bucketNo); 00164 return ErrLockTimeOut; 00165 } 00166 HashIndexNode *head = (HashIndexNode*) bucket->bucketList_; 00167 if (info->isUnique) 00168 { 00169 BucketList list(head); 00170 BucketIter iter = list.getIterator(); 00171 HashIndexNode *node; 00172 void *bucketTuple; 00173 printDebug(DM_HashIndex, "HashIndex insert Checking for unique"); 00174 while((node = iter.next()) != NULL) 00175 { 00176 bucketTuple = node->ptrToTuple_; 00177 if (AllDataType::compareVal((void*)((char*)bucketTuple +offset), 00178 (void*)((char*)tuple +offset), OpEquals,type, length)) 00179 { 00180 printError(ErrUnique, "Unique key violation"); 00181 bucket->mutex_.releaseLock(tbl->db_->procSlot); 00182 return ErrUnique; 00183 } 00184 } 00185 } 00186 00187 printDebug(DM_HashIndex, "HashIndex insert into bucket list"); 00188 if (!head) 00189 { 00190 printDebug(DM_HashIndex, "HashIndex insert head is empty"); 00191 DbRetVal rv = OK; 00192 HashIndexNode *firstNode= (HashIndexNode*)(((Chunk*)iptr->hashNodeChunk_)->allocate(tbl->db_, &rv)); 00193 if (firstNode == NULL) 00194 { 00195 bucket->mutex_.releaseLock(tbl->db_->procSlot); 00196 return rv; 00197 } 00198 firstNode->ptrToKey_ = keyPtr; 00199 firstNode->ptrToTuple_ = tuple; 00200 firstNode->next_ = NULL; 00201 bucket->bucketList_ = (HashIndexNode*)firstNode; 00202 printDebug(DM_HashIndex, "HashIndex insert new node %x in empty bucket", bucket->bucketList_); 00203 } 00204 else 00205 { 00206 BucketList list(head); 00207 rc = list.insert((Chunk*)iptr->hashNodeChunk_, tbl->db_, keyPtr, tuple); 00208 if (rc !=OK) { 00209 bucket->mutex_.releaseLock(tbl->db_->procSlot); 00210 printf("PRABA::bucket insert failed here with rc %d\n", rc); 00211 return rc; 00212 } 00213 00214 } 00215 if (undoFlag) { 00216 00217 rc = tr->appendLogicalUndoLog(tbl->sysDB_, InsertHashIndexOperation, 00218 tuple, sizeof(void*), indexPtr); 00219 if (rc !=OK) 00220 { 00221 BucketList list(head); 00222 rc = list.remove((Chunk*)iptr->hashNodeChunk_, tbl->db_, keyPtr); 00223 if (rc !=OK) printError(ErrSysFatal, "double failure on undo log insert followed by hash bucket list remove\n"); 00224 } 00225 } 00226 00227 bucket->mutex_.releaseLock(tbl->db_->procSlot); 00228 return rc; 00229 }
Here is the call graph for this function:
| DbRetVal HashIndex::remove | ( | TableImpl * | tbl, | |
| Transaction * | tr, | |||
| void * | indexPtr, | |||
| IndexInfo * | info, | |||
| void * | tuple, | |||
| bool | undoFlag | |||
| ) | [virtual] |
Implements Index.
Definition at line 233 of file HashIndex.cxx.
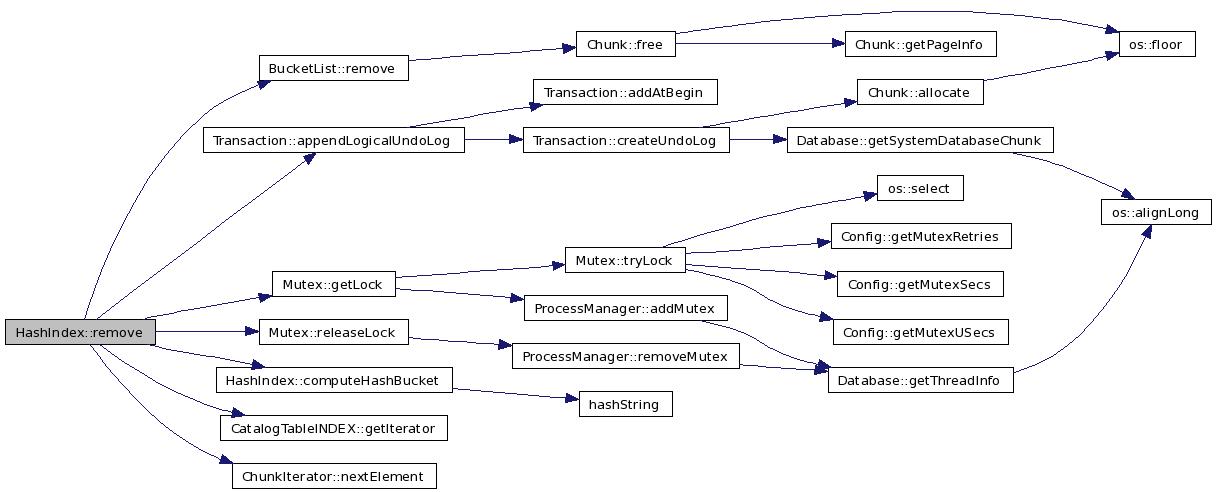
References Transaction::appendLogicalUndoLog(), Bucket::bucketList_, computeHashBucket(), TableImpl::db_, DeleteHashIndexOperation, DM_HashIndex, ErrLockTimeOut, ErrNotExists, ErrWarning, SingleFieldHashIndexInfo::fldName, CatalogTableINDEX::getIterator(), Mutex::getLock(), INDEX::hashNodeChunk_, Bucket::mutex_, ChunkIterator::nextElement(), SingleFieldHashIndexInfo::noOfBuckets, SingleFieldHashIndexInfo::offset, OK, printDebug, printError, Database::procSlot, Mutex::releaseLock(), BucketList::remove(), SplCase, TableImpl::sysDB_, and SingleFieldHashIndexInfo::type.
00234 { 00235 INDEX *iptr = (INDEX*)indexPtr; 00236 00237 SingleFieldHashIndexInfo *info = (SingleFieldHashIndexInfo*) indInfo; 00238 DataType type = info->type; 00239 char *name = info->fldName; 00240 int offset = info->offset; 00241 int noOfBuckets = info->noOfBuckets; 00242 00243 printDebug(DM_HashIndex, "Removing hash index node for field %s", name); 00244 ChunkIterator citer = CatalogTableINDEX::getIterator(indexPtr); 00245 Bucket* buckets = (Bucket*)citer.nextElement(); 00246 void *keyPtr =(void*)((char*)tuple + offset); 00247 00248 int bucket = HashIndex::computeHashBucket(type, keyPtr, noOfBuckets); 00249 00250 Bucket *bucket1 = &buckets[bucket]; 00251 00252 int ret = bucket1->mutex_.getLock(tbl->db_->procSlot); 00253 if (ret != 0) 00254 { 00255 printError(ErrLockTimeOut,"Unable to acquire bucket Mutex for bucket %d",bucket); 00256 return ErrLockTimeOut; 00257 } 00258 HashIndexNode *head = (HashIndexNode*) bucket1->bucketList_; 00259 00260 if (!head) { printError(ErrNotExists, "Hash index does not exist:should never happen\n"); return ErrNotExists; } 00261 BucketList list(head); 00262 printDebug(DM_HashIndex, "Removing hash index node from head %x", head); 00263 00264 DbRetVal rc = list.remove((Chunk*)iptr->hashNodeChunk_, tbl->db_, keyPtr); 00265 if (SplCase == rc) 00266 { 00267 printDebug(DM_HashIndex, "Removing hash index node from head with only none node"); 00268 printError(ErrWarning, "Removing hash index node from head with only none node"); 00269 bucket1->bucketList_ = 0; 00270 rc = OK; 00271 } 00272 if (undoFlag) { 00273 rc =tr->appendLogicalUndoLog(tbl->sysDB_, DeleteHashIndexOperation, 00274 tuple, sizeof(void*), indexPtr); 00275 if (rc !=OK) 00276 { 00277 //TODO::add it back to the bucketlist 00278 } 00279 } 00280 bucket1->mutex_.releaseLock(tbl->db_->procSlot); 00281 return rc; 00282 }
Here is the call graph for this function:
| DbRetVal HashIndex::update | ( | TableImpl * | tbl, | |
| Transaction * | tr, | |||
| void * | indexPtr, | |||
| IndexInfo * | info, | |||
| void * | tuple, | |||
| bool | undoFlag | |||
| ) | [virtual] |
Implements Index.
Definition at line 285 of file HashIndex.cxx.
References Transaction::appendLogicalUndoLog(), Bucket::bucketList_, AllDataType::compareVal(), computeHashBucket(), TableImpl::db_, DeleteHashIndexOperation, DM_HashIndex, ErrLockTimeOut, ErrSysInternal, TableImpl::fldList_, SingleFieldHashIndexInfo::fldName, CatalogTableINDEX::getIterator(), FieldList::getIterator(), Mutex::getLock(), FieldIterator::hasElement(), INDEX::hashNodeChunk_, BucketList::insert(), InsertHashIndexOperation, Bucket::mutex_, HashIndexNode::next_, ChunkIterator::nextElement(), FieldIterator::nextElement(), SingleFieldHashIndexInfo::noOfBuckets, SingleFieldHashIndexInfo::offset, OK, OpEquals, printDebug, printError, Database::procSlot, HashIndexNode::ptrToKey_, HashIndexNode::ptrToTuple_, Mutex::releaseLock(), BucketList::remove(), TableImpl::sysDB_, and SingleFieldHashIndexInfo::type.
00286 { 00287 INDEX *iptr = (INDEX*)indexPtr; 00288 00289 SingleFieldHashIndexInfo *info = (SingleFieldHashIndexInfo*) indInfo; 00290 DataType type = info->type; 00291 char *name = info->fldName; 00292 int offset = info->offset; 00293 int noOfBuckets = info->noOfBuckets; 00294 00295 printDebug(DM_HashIndex, "Updating hash index node for field %s", name); 00296 00297 //check whether the index key is updated or not 00298 //if it is not updated return from here 00299 void *keyPtr =(void*)((char*)tuple + offset); 00300 //Iterate through the bind list and check 00301 FieldIterator fldIter = tbl->fldList_.getIterator(); 00302 void *newKey = NULL; 00303 while (fldIter.hasElement()) 00304 { 00305 FieldDef def = fldIter.nextElement(); 00306 if (0 == strcmp(def.fldName_, name)) 00307 { 00308 if (NULL == def.bindVal_) 00309 return OK; 00310 bool result = AllDataType::compareVal(keyPtr, def.bindVal_, 00311 OpEquals, def.type_, def.length_); 00312 if (result) return OK; else newKey = def.bindVal_; 00313 } 00314 } 00315 printDebug(DM_HashIndex, "Updating hash index node: Key value is updated"); 00316 00317 if (newKey == NULL) 00318 { 00319 printError(ErrSysInternal,"Internal Error:: newKey is Null"); 00320 return ErrSysInternal; 00321 } 00322 ChunkIterator citer = CatalogTableINDEX::getIterator(indexPtr); 00323 00324 Bucket* buckets = (Bucket*)citer.nextElement(); 00325 00326 //remove the node whose key is updated 00327 int bucketNo = computeHashBucket(type, 00328 keyPtr, noOfBuckets); 00329 printDebug(DM_HashIndex, "Updating hash index node: Bucket for old value is %d", bucketNo); 00330 Bucket *bucket = &buckets[bucketNo]; 00331 00332 //it may run into deadlock, when two threads updates tuples which falls in 00333 //same buckets.So take both the mutex one after another, which will reduce the 00334 //deadlock window. 00335 int ret = bucket->mutex_.getLock(tbl->db_->procSlot); 00336 if (ret != 0) 00337 { 00338 printError(ErrLockTimeOut,"Unable to acquire bucket Mutex for bucket %d",bucketNo); 00339 return ErrLockTimeOut; 00340 } 00341 //insert node for the updated key value 00342 int newBucketNo = computeHashBucket(type, 00343 newKey, noOfBuckets); 00344 printDebug(DM_HashIndex, "Updating hash index node: Bucket for new value is %d", newBucketNo); 00345 00346 Bucket *bucket1 = &buckets[newBucketNo]; 00347 bucket1->mutex_.getLock(tbl->db_->procSlot); 00348 if (ret != 0) 00349 { 00350 printError(ErrLockTimeOut,"Unable to acquire bucket Mutex for bucket %d",newBucketNo); 00351 return ErrLockTimeOut; 00352 } 00353 00354 HashIndexNode *head1 = (HashIndexNode*) bucket->bucketList_; 00355 if (head1) 00356 { 00357 BucketList list1(head1); 00358 printDebug(DM_HashIndex, "Updating hash index node: Removing node from list with head %x", head1); 00359 list1.remove((Chunk*)iptr->hashNodeChunk_, tbl->db_, keyPtr); 00360 } 00361 else 00362 { 00363 printError(ErrSysInternal,"Update: Bucket list is null"); 00364 return ErrSysInternal; 00365 } 00366 DbRetVal rc = OK; 00367 if (undoFlag) { 00368 rc = tr->appendLogicalUndoLog(tbl->sysDB_, DeleteHashIndexOperation, 00369 tuple, sizeof(void*), indexPtr); 00370 if (rc !=OK) 00371 { 00372 //TODO::add it back to the bucket list 00373 bucket1->mutex_.releaseLock(tbl->db_->procSlot); 00374 bucket->mutex_.releaseLock(tbl->db_->procSlot); 00375 return rc; 00376 } 00377 } 00378 HashIndexNode *head2 = (HashIndexNode*) bucket1->bucketList_; 00379 //Note:: the tuple will be in the same address location 00380 //so not changing the keyptr and tuple during append 00381 //only bucket where this node resides will only change 00382 //if the index key is updated. 00383 if (!head2) 00384 { 00385 DbRetVal rv = OK; 00386 HashIndexNode *firstNode= (HashIndexNode*)(((Chunk*)iptr->hashNodeChunk_)->allocate(tbl->db_, &rv)); 00387 if (firstNode == NULL) 00388 { 00389 printError(rv, "Error in allocating hash node"); 00390 bucket1->mutex_.releaseLock(tbl->db_->procSlot); 00391 bucket->mutex_.releaseLock(tbl->db_->procSlot); 00392 return rv; 00393 } 00394 firstNode->ptrToKey_ = keyPtr; 00395 firstNode->ptrToTuple_ = tuple; 00396 firstNode->next_ = NULL; 00397 bucket1->bucketList_ = (HashIndexNode*)firstNode; 00398 printDebug(DM_HashIndex, "Updating hash index node: Adding new node %x:Head is empty", firstNode); 00399 } 00400 else 00401 { 00402 BucketList list2(head2); 00403 printDebug(DM_HashIndex, "Updating hash index node: Adding node to list with head %x", head2); 00404 list2.insert((Chunk*)iptr->hashNodeChunk_, tbl->db_, keyPtr, tuple); 00405 } 00406 if (undoFlag) { 00407 00408 rc = tr->appendLogicalUndoLog(tbl->sysDB_, InsertHashIndexOperation, 00409 tuple, sizeof(void*), indexPtr); 00410 if (rc !=OK) 00411 { 00412 //TODO::revert back the changes:delete and add the node + remove the logical undo log 00413 //of the DeleteHashIndexOperation 00414 } 00415 } 00416 bucket1->mutex_.releaseLock(tbl->db_->procSlot); 00417 bucket->mutex_.releaseLock(tbl->db_->procSlot); 00418 return rc; 00419 }
Here is the call graph for this function: